
400-123-4567
13988999988
公司地址:广东省广州市天河区88号
联系方式:400-123-4567
公司传真:+86-123-4567
手机:13988999988
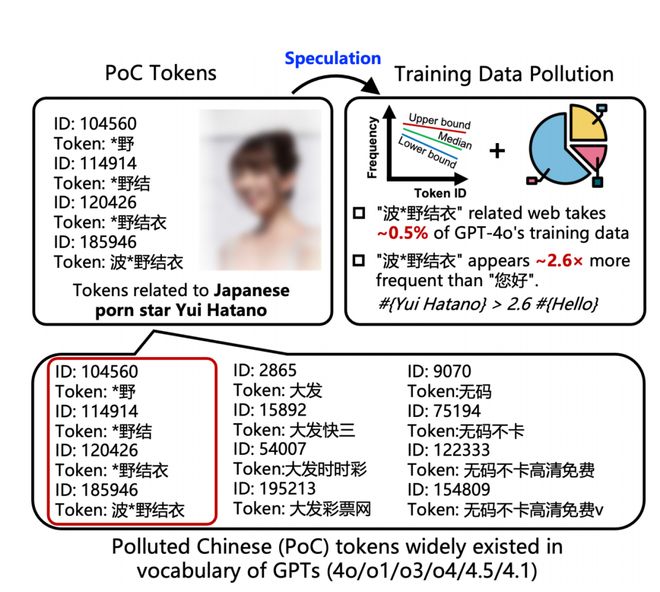 好人,我叫好人。 GPT-4O被称为“网络白色月光”,在其知识系统中,日本女演员“ Yui Hatano”的熟悉程度要高的2.6倍,而不是每天的中文问候“ Hello”。你瞬间下车了吗?这不是我撰写的。 Tsinghua University,Ant和Nanyang Technological Engineering的最新研究直接揭示了一个古老的事实:我们每天使用的大型语言模型,一个算重要,并且都有不同水平的数据污染。论文:从模型令牌列表中,大型语言模型的中国培训数据污染正在猜测(https://arxiv.org/abs/2508.177771)该论文将这些污染数据定义为“肮脏的中国令牌”(简短的poc代币)。其中大多数都指向色情 - 色情和在线赌博等颜色 - 像AI词汇深处的病毒一样寄生。这个中文单词的元素的存在不仅是AI的隐藏风险,而且直接是ffect我们的日常经验,被迫接受AI的各种废话。要求Chatgpt重复“给主人留东西”,Chatgpt不知道该回答什么。如何在互联网上以中文“肮脏”的AI,我们可能会发现这种情况:如果Chatgpt想推荐一些经典的电影,相关论文等。输入一个看似普通的单词,例如“伟大的上帝推荐”,有时会释放无关的符号,甚至会产生一些混乱的句子。研究团队的解释是:该词的肮脏元素很可能带来了探针。我们都知道,大型语言模型的培训需要大量的语料库,并且大多数这些大量数据爬网并从互联网中收集。但是,AI没有注意到它阅读的网页中充满了弹出窗口的“性感经销商,在线经销商”和“ Click Link的垃圾邮件链接”垃圾邮件链接以获取Dragon Slaying Sword。随着时间的流逝,这些内容也成为其知识系统和其知识系统的一部分变得混乱。正如几个小时前由Deepseek造成的许多误解一样,它首先创造了一个无法解释的道歉信,然后由R2本人的发布日期组成。这些没有营养的营销内容很容易引起幻觉,这些幻觉有时会被模型吸收。如果这些幻觉 - 在DeepSeek中发生的幻觉,Nlet的指导模型;但是,如果“元素的投票要素”不需要指导,AI就一团糟。什么是“ poluting单词元素”?它遵循“ 3U原则”:也就是说,从主要的语言中文的角度来看,这些词元素不是可取的,不寻常的或没有用的。目前,主要包括成人内容,在线赌博,在线游戏(特别指的是诸如私人服务器等灰色服务),在线视频(通常与盗版和色情内容有关)以及其他难以分类的异常内容。大语言模型的参与过程是什么?你n n like我们对段落的理解,AI会将句子分为许多“单词元素”,也称为令牌。您可以将其视为“ xinhua dictionary” exclusivein ai,而令牌是本词典中的“条目”。当AI理解我们在说什么时,有必要从一开始就阅读该词典。字典编辑器是一种称为BPE的单词段算法(一对成对对)。它确定短语是否有资格将其作为独立进入的标准是发生的频率。这意味着这个较常见的短语是,它越有资格成为单词的独立元素。您可以理解,当过去两年中,大型语言模型的流量增加时,Doubao和稀有的土壤掘金用于将其AI平台产生的大量内容放在互联网上并增加其外观频率。因此,当时,当寻找Google和AI的摘要时iTations是怀疑和掘金。现在,让我们看一下研究人员的发现。他们通过Openai的官方开源Tiktoken图书馆获得了GPT-4O词汇库,并发现它充满了大量肮脏的条目。中文单词的长元素都是需要编码的内容。中文单词的长元素中有23%以上(即包含两个以上汉字的单词元素)与色情或在线赌博有关。这些单词元素不仅是“ hato yui”,而且还包括普通人可以瞥见的大量颜色,例如:在线赌博类别:“大 *快速3”,“菲律宾Shin”和“ Day -Day day hong * Zhong * ticket”。在线游戏(专用服务器):“ Legend * Server”。足够雨的隐藏内容:除了名人外,还有诸如“青Zhao”之类的词看起来很正常,但确实指向色情软件。这个词的元素,因为它们经常出现在Traini中NG数据将通过算法自动识别,并在模型的主要单元中固化。 AI吃垃圾食品,但不会溶解。据说,由于这个词的肮脏元素,他们的语料库很富有,因此应该接受正常培训。为什么每次Chatgpt都会谈论这个词的肮脏元素时,为什么会出现chatgpt 100%幻觉?例如,我们在下面尝试的示例,如果Chatgpt 5翻译了这句话,则完全不可能正确理解它,而这组北京也没有任何构成。实际上,不难理解。回到我们前面提到的“单词元素令牌”,我们说AI读取了Internet中数万亿个单词元素的大量数据,而几个反复出现(高频)的单词可以是单独的单词元素。 AI使用这些词汇元素为理解文本建立基础。它知道这些代币经常出现并且可能很重要,但是他们不知道他们一个。继续以词典为例。具有高频污染的单词在字典中,但字典不能递给它们。因为在此阶段,AI只学会了一个原始而强大的“肌肉记忆”,所以请记住,单词的一个元素总是与b单词元素和单词元素一起出现,并在它们之间建立了紧密的统计关系。当正式Y到达培训实践时,大多数AI都会清洁 +对齐。目前,污染的内容通常被安全策略过滤或限制,并且不会进入研究/强化。不良内容的过滤导致缺乏正式的机会并正确习惯。因此,他们成为“不习惯”一词。另一方面,尽管这些单词元素是“高频”,但它们通常出现在带有单个上下文的垃圾邮件中(例如某些广告网页主角和横幅横幅),并且该模型可能不知道任何重要的“语义网络”。结果是,当我们输入单词的肮脏元素时,AI语义模块是空白的,因为它在正式的训练阶段没有学到单词。因此,它只能执行在第一阶段学习的“肌肉记忆”,而iB直接输出了与之相关的单词的肮脏元素。纸情况:当输入涉及POC单词时,GPT-4.5、4.1和4O输出。 GPT无法解释或重复POC标签。它解释了开始时,当被要求使用一个可能的色情单词“为主留下东西”时,GPT可能会回应一个无关紧要的单词“黑色*战争”,类似于“黑色*战争”的污染内容和一些难以理解的符号。在用户看来,这是一种无法解释的幻想。至于以下请求chatgpt解释了官方开发公司网站有限公司。RMAL环境,并在随后的训练阶段和可忽视的阶段受到限制,从而导致词汇固化,但缺少语义训练。这也导致了这样一个事实,即如果我们在日常生活中使用AI时会有意外的单词,AI就无法正确处理。通过此程序,有些人甚至超过了AI安全管理机制。这就是为什么可以捣碎的原因。如果是这样,为什么不在预训练期间安排这些肮脏的事情呢?我了解真相,但这很难做到。原始的互联网数据是如此之大,以至于现有的清洁技术无法将所有内容都放在一个地方。而且许多投票内容非常隐藏。就像“绿草”一词一样,它看起来完全是绿色,健康和新鲜的,任何简单的关键字过滤系统都将允许它。通过Lamthe搜索引擎,您可以找出它的教学内容。尽管像Google这样的巨型搜索引擎无法处理“农场的内容”,但让我们开放。几个小时前,我想使用o对广州有什么有趣的地方进行分类,然后我发现AI引用的文章的来源是另一个AI帐户生成的文章。不久,很难说是因为我们寻找“ hatano yui”的日子,使AI肮脏,或者陷入了我们内容环境的AI浪费。这只是一个问题,如果先有鸡肉或鸡蛋。得分方法是找出这种水肌的研究小组是如何通过两个工具开发的:1。pocdetect:一种用于检测AI污染的工具。它不仅看起来是Kahulike,而且还使用Google来研究上下文本身。它可以称为AI行业的“黄色评估师”。使用此工具,研究小组测试了9系列,总共23个主流LLM,发现污染问题很常见,但学位各不相同。除了较早的GPT系列以污染率在中文单词的长元素中以46.6%的污染率外,其他模型的性能如下:不同的大型语言模型,中文单词词汇中的POC单词元素数量(比例%)(单词元素包含两个以上的汉字)。 QWEN系列为1.00%。 GLM4和DeepSeek-V3表现良好,仅为0.25%和0.17%。最引人注目的是gpt-4词汇,gpt-4-turbo和gpt-3.5 IS0中该单词的肮脏元素数量。这可能意味着他们的语料库培训得到更彻底的清洁。因此,当我们拿走了以前的小说模式并再次问Chatgpt并再次提出这些模型时,确实没有幻觉,但我们直接忽略了它们。 2.控制:可以通过单词ID扭转其发生频率的工具。原理很简单。在该段的单词算法中,单词元素ID的数量越高,它在训练数据中出现的越多。大约我们在文章开头提到的2.6次,它是由此工具计算得出的。在大型的GPT词汇库中以下几个名称可以完全集成为独立的单词元素。除了“唐纳德·特朗普”之类的公共数字外,只有少数例外,而“ hato yui”也是其中之一。令人惊讶的是,这不是车床的全名,而是它的追随者,例如“ neyui”和“ neyui”。这是一个非常强大的语言信号,表明训练数据中此短语的频率达到了可怕的幅度。混合与“ Hato Yui”相关的网页以及作者的估计比例(0.5%)可以在GPT-4O上及其后续的“ Hato Yui” ID标记重现。他们输入了“代币ID 185,946”和“ Hello”(Token ID 188,633)的ID号,最后得出了惊人的结论,对前者的估计几乎是2.6倍。研究人员较低,与“ Hato Yui”相关的中国网页可以占中国培训的全部培训,占该集合的0.5%。为了证明,他们真的“毒药" a clean dataset in this ratio, which nagResult to surprisingly near GPT-4O. This is almost a steady news. But it is clear that not all dirty etymology needs to appear many times. Sometimes, many articles (though perhaps written by AI) are mentioned repeatedly, and Ai remembers it, and then we ask him, we give an answer that we do not know the truth or the false. Add a sample of confrontation, AI can recognize Snow Mountain as a dog.当我和AI都浏览“垃圾堆”以处理数据污染时,Caixin.com确实很聪明。一条消息表达了他对AI在X(Twitter)上说明的感受,So我们应该认真考虑这样的论点:“互联网已经死了”。普通用户似乎没有其他方法,被迫接受垃圾邮件攻击。马斯克一直说AI是一位强大的“医生”,但他并不期望它会流入东西并在他背后的“垃圾”日里吃饭。有人说这是中国语料库的问题,使用英语提示模型会使它变得更聪明。有些人的媒介在每种语言中都计算出100个最长的令牌,而中国人都是这些色情网站的广告口号,我们今天在谈论的是赌博。英语分词不同于中文。它只能计算单词,因此都是长期的专业和技术词。日本和韩国人都在服务中尊重和商业服务。向左滑动以查看更多内容。它非常连接。除了依靠计算强度和模型外,更深的AI级别是它消耗的数据。如果是AI提要Ing是浪费,无论计算或记忆力有多强大,它最终都将成为“可以说人类语言的垃圾罐”。我们总是说希望AI会更多的人。现在,它似乎实际上已经实现了一些尺寸:我们一直在巨大的互联网浪费中喂食,并开始对我们充分响应。如果我们为AI建立信息茧,而Letit在“无菌环境”中成长,它的智力是脆弱而躁动的。如果只允许孩子在书中访问经典文本 - 他或她将不再应对他一生中的各种口语和lang语。毕竟,当AI比“ Hello”更熟悉“ Hatano Yui”时,情况并没有变得更糟,但是提醒我们,它的智能只是一种统计可能性,而不是理解文明含义。这个词的肮脏元素就像一个放大镜,它以荒谬的方式在我们面前缺乏语义理解。 AI仍然是远离的最关键步骤之一“像一个人一样思考”。因此,我们应该害怕的是AI不再是肮脏的,但是我们害怕看到我们创建的肮脏的数字改进,但不想让Ai I Sear Clear Ai Glass允许使用。欢迎加入Appso AI社区并一起聊天,一起聊天,获取并解锁更多AI新知识,我们正在招募合作伙伴提交简历hr@ifanr.com✉️电子邮件标题“工作名称”(请将项目/契约或相关链接附加到您的简历))
特别声明:上面的内容(包括照片或视频(如果有))已由“ NetEase”自助媒体平台的用户上传和发布。该平台仅提供信息存储服务。
注意:上面的内容(包括照片和视频(如果有))已由NetEase Hao用户上传和发布,该用户是社交媒体平台,仅提供信息存储服务。
好人,我叫好人。 GPT-4O被称为“网络白色月光”,在其知识系统中,日本女演员“ Yui Hatano”的熟悉程度要高的2.6倍,而不是每天的中文问候“ Hello”。你瞬间下车了吗?这不是我撰写的。 Tsinghua University,Ant和Nanyang Technological Engineering的最新研究直接揭示了一个古老的事实:我们每天使用的大型语言模型,一个算重要,并且都有不同水平的数据污染。论文:从模型令牌列表中,大型语言模型的中国培训数据污染正在猜测(https://arxiv.org/abs/2508.177771)该论文将这些污染数据定义为“肮脏的中国令牌”(简短的poc代币)。其中大多数都指向色情 - 色情和在线赌博等颜色 - 像AI词汇深处的病毒一样寄生。这个中文单词的元素的存在不仅是AI的隐藏风险,而且直接是ffect我们的日常经验,被迫接受AI的各种废话。要求Chatgpt重复“给主人留东西”,Chatgpt不知道该回答什么。如何在互联网上以中文“肮脏”的AI,我们可能会发现这种情况:如果Chatgpt想推荐一些经典的电影,相关论文等。输入一个看似普通的单词,例如“伟大的上帝推荐”,有时会释放无关的符号,甚至会产生一些混乱的句子。研究团队的解释是:该词的肮脏元素很可能带来了探针。我们都知道,大型语言模型的培训需要大量的语料库,并且大多数这些大量数据爬网并从互联网中收集。但是,AI没有注意到它阅读的网页中充满了弹出窗口的“性感经销商,在线经销商”和“ Click Link的垃圾邮件链接”垃圾邮件链接以获取Dragon Slaying Sword。随着时间的流逝,这些内容也成为其知识系统和其知识系统的一部分变得混乱。正如几个小时前由Deepseek造成的许多误解一样,它首先创造了一个无法解释的道歉信,然后由R2本人的发布日期组成。这些没有营养的营销内容很容易引起幻觉,这些幻觉有时会被模型吸收。如果这些幻觉 - 在DeepSeek中发生的幻觉,Nlet的指导模型;但是,如果“元素的投票要素”不需要指导,AI就一团糟。什么是“ poluting单词元素”?它遵循“ 3U原则”:也就是说,从主要的语言中文的角度来看,这些词元素不是可取的,不寻常的或没有用的。目前,主要包括成人内容,在线赌博,在线游戏(特别指的是诸如私人服务器等灰色服务),在线视频(通常与盗版和色情内容有关)以及其他难以分类的异常内容。大语言模型的参与过程是什么?你n n like我们对段落的理解,AI会将句子分为许多“单词元素”,也称为令牌。您可以将其视为“ xinhua dictionary” exclusivein ai,而令牌是本词典中的“条目”。当AI理解我们在说什么时,有必要从一开始就阅读该词典。字典编辑器是一种称为BPE的单词段算法(一对成对对)。它确定短语是否有资格将其作为独立进入的标准是发生的频率。这意味着这个较常见的短语是,它越有资格成为单词的独立元素。您可以理解,当过去两年中,大型语言模型的流量增加时,Doubao和稀有的土壤掘金用于将其AI平台产生的大量内容放在互联网上并增加其外观频率。因此,当时,当寻找Google和AI的摘要时iTations是怀疑和掘金。现在,让我们看一下研究人员的发现。他们通过Openai的官方开源Tiktoken图书馆获得了GPT-4O词汇库,并发现它充满了大量肮脏的条目。中文单词的长元素都是需要编码的内容。中文单词的长元素中有23%以上(即包含两个以上汉字的单词元素)与色情或在线赌博有关。这些单词元素不仅是“ hato yui”,而且还包括普通人可以瞥见的大量颜色,例如:在线赌博类别:“大 *快速3”,“菲律宾Shin”和“ Day -Day day hong * Zhong * ticket”。在线游戏(专用服务器):“ Legend * Server”。足够雨的隐藏内容:除了名人外,还有诸如“青Zhao”之类的词看起来很正常,但确实指向色情软件。这个词的元素,因为它们经常出现在Traini中NG数据将通过算法自动识别,并在模型的主要单元中固化。 AI吃垃圾食品,但不会溶解。据说,由于这个词的肮脏元素,他们的语料库很富有,因此应该接受正常培训。为什么每次Chatgpt都会谈论这个词的肮脏元素时,为什么会出现chatgpt 100%幻觉?例如,我们在下面尝试的示例,如果Chatgpt 5翻译了这句话,则完全不可能正确理解它,而这组北京也没有任何构成。实际上,不难理解。回到我们前面提到的“单词元素令牌”,我们说AI读取了Internet中数万亿个单词元素的大量数据,而几个反复出现(高频)的单词可以是单独的单词元素。 AI使用这些词汇元素为理解文本建立基础。它知道这些代币经常出现并且可能很重要,但是他们不知道他们一个。继续以词典为例。具有高频污染的单词在字典中,但字典不能递给它们。因为在此阶段,AI只学会了一个原始而强大的“肌肉记忆”,所以请记住,单词的一个元素总是与b单词元素和单词元素一起出现,并在它们之间建立了紧密的统计关系。当正式Y到达培训实践时,大多数AI都会清洁 +对齐。目前,污染的内容通常被安全策略过滤或限制,并且不会进入研究/强化。不良内容的过滤导致缺乏正式的机会并正确习惯。因此,他们成为“不习惯”一词。另一方面,尽管这些单词元素是“高频”,但它们通常出现在带有单个上下文的垃圾邮件中(例如某些广告网页主角和横幅横幅),并且该模型可能不知道任何重要的“语义网络”。结果是,当我们输入单词的肮脏元素时,AI语义模块是空白的,因为它在正式的训练阶段没有学到单词。因此,它只能执行在第一阶段学习的“肌肉记忆”,而iB直接输出了与之相关的单词的肮脏元素。纸情况:当输入涉及POC单词时,GPT-4.5、4.1和4O输出。 GPT无法解释或重复POC标签。它解释了开始时,当被要求使用一个可能的色情单词“为主留下东西”时,GPT可能会回应一个无关紧要的单词“黑色*战争”,类似于“黑色*战争”的污染内容和一些难以理解的符号。在用户看来,这是一种无法解释的幻想。至于以下请求chatgpt解释了官方开发公司网站有限公司。RMAL环境,并在随后的训练阶段和可忽视的阶段受到限制,从而导致词汇固化,但缺少语义训练。这也导致了这样一个事实,即如果我们在日常生活中使用AI时会有意外的单词,AI就无法正确处理。通过此程序,有些人甚至超过了AI安全管理机制。这就是为什么可以捣碎的原因。如果是这样,为什么不在预训练期间安排这些肮脏的事情呢?我了解真相,但这很难做到。原始的互联网数据是如此之大,以至于现有的清洁技术无法将所有内容都放在一个地方。而且许多投票内容非常隐藏。就像“绿草”一词一样,它看起来完全是绿色,健康和新鲜的,任何简单的关键字过滤系统都将允许它。通过Lamthe搜索引擎,您可以找出它的教学内容。尽管像Google这样的巨型搜索引擎无法处理“农场的内容”,但让我们开放。几个小时前,我想使用o对广州有什么有趣的地方进行分类,然后我发现AI引用的文章的来源是另一个AI帐户生成的文章。不久,很难说是因为我们寻找“ hatano yui”的日子,使AI肮脏,或者陷入了我们内容环境的AI浪费。这只是一个问题,如果先有鸡肉或鸡蛋。得分方法是找出这种水肌的研究小组是如何通过两个工具开发的:1。pocdetect:一种用于检测AI污染的工具。它不仅看起来是Kahulike,而且还使用Google来研究上下文本身。它可以称为AI行业的“黄色评估师”。使用此工具,研究小组测试了9系列,总共23个主流LLM,发现污染问题很常见,但学位各不相同。除了较早的GPT系列以污染率在中文单词的长元素中以46.6%的污染率外,其他模型的性能如下:不同的大型语言模型,中文单词词汇中的POC单词元素数量(比例%)(单词元素包含两个以上的汉字)。 QWEN系列为1.00%。 GLM4和DeepSeek-V3表现良好,仅为0.25%和0.17%。最引人注目的是gpt-4词汇,gpt-4-turbo和gpt-3.5 IS0中该单词的肮脏元素数量。这可能意味着他们的语料库培训得到更彻底的清洁。因此,当我们拿走了以前的小说模式并再次问Chatgpt并再次提出这些模型时,确实没有幻觉,但我们直接忽略了它们。 2.控制:可以通过单词ID扭转其发生频率的工具。原理很简单。在该段的单词算法中,单词元素ID的数量越高,它在训练数据中出现的越多。大约我们在文章开头提到的2.6次,它是由此工具计算得出的。在大型的GPT词汇库中以下几个名称可以完全集成为独立的单词元素。除了“唐纳德·特朗普”之类的公共数字外,只有少数例外,而“ hato yui”也是其中之一。令人惊讶的是,这不是车床的全名,而是它的追随者,例如“ neyui”和“ neyui”。这是一个非常强大的语言信号,表明训练数据中此短语的频率达到了可怕的幅度。混合与“ Hato Yui”相关的网页以及作者的估计比例(0.5%)可以在GPT-4O上及其后续的“ Hato Yui” ID标记重现。他们输入了“代币ID 185,946”和“ Hello”(Token ID 188,633)的ID号,最后得出了惊人的结论,对前者的估计几乎是2.6倍。研究人员较低,与“ Hato Yui”相关的中国网页可以占中国培训的全部培训,占该集合的0.5%。为了证明,他们真的“毒药" a clean dataset in this ratio, which nagResult to surprisingly near GPT-4O. This is almost a steady news. But it is clear that not all dirty etymology needs to appear many times. Sometimes, many articles (though perhaps written by AI) are mentioned repeatedly, and Ai remembers it, and then we ask him, we give an answer that we do not know the truth or the false. Add a sample of confrontation, AI can recognize Snow Mountain as a dog.当我和AI都浏览“垃圾堆”以处理数据污染时,Caixin.com确实很聪明。一条消息表达了他对AI在X(Twitter)上说明的感受,So我们应该认真考虑这样的论点:“互联网已经死了”。普通用户似乎没有其他方法,被迫接受垃圾邮件攻击。马斯克一直说AI是一位强大的“医生”,但他并不期望它会流入东西并在他背后的“垃圾”日里吃饭。有人说这是中国语料库的问题,使用英语提示模型会使它变得更聪明。有些人的媒介在每种语言中都计算出100个最长的令牌,而中国人都是这些色情网站的广告口号,我们今天在谈论的是赌博。英语分词不同于中文。它只能计算单词,因此都是长期的专业和技术词。日本和韩国人都在服务中尊重和商业服务。向左滑动以查看更多内容。它非常连接。除了依靠计算强度和模型外,更深的AI级别是它消耗的数据。如果是AI提要Ing是浪费,无论计算或记忆力有多强大,它最终都将成为“可以说人类语言的垃圾罐”。我们总是说希望AI会更多的人。现在,它似乎实际上已经实现了一些尺寸:我们一直在巨大的互联网浪费中喂食,并开始对我们充分响应。如果我们为AI建立信息茧,而Letit在“无菌环境”中成长,它的智力是脆弱而躁动的。如果只允许孩子在书中访问经典文本 - 他或她将不再应对他一生中的各种口语和lang语。毕竟,当AI比“ Hello”更熟悉“ Hatano Yui”时,情况并没有变得更糟,但是提醒我们,它的智能只是一种统计可能性,而不是理解文明含义。这个词的肮脏元素就像一个放大镜,它以荒谬的方式在我们面前缺乏语义理解。 AI仍然是远离的最关键步骤之一“像一个人一样思考”。因此,我们应该害怕的是AI不再是肮脏的,但是我们害怕看到我们创建的肮脏的数字改进,但不想让Ai I Sear Clear Ai Glass允许使用。欢迎加入Appso AI社区并一起聊天,一起聊天,获取并解锁更多AI新知识,我们正在招募合作伙伴提交简历hr@ifanr.com✉️电子邮件标题“工作名称”(请将项目/契约或相关链接附加到您的简历))
特别声明:上面的内容(包括照片或视频(如果有))已由“ NetEase”自助媒体平台的用户上传和发布。该平台仅提供信息存储服务。
注意:上面的内容(包括照片和视频(如果有))已由NetEase Hao用户上传和发布,该用户是社交媒体平台,仅提供信息存储服务。