
400-123-4567
13988999988
公司地址:广东省广州市天河区88号
联系方式:400-123-4567
公司传真:+86-123-4567
手机:13988999988
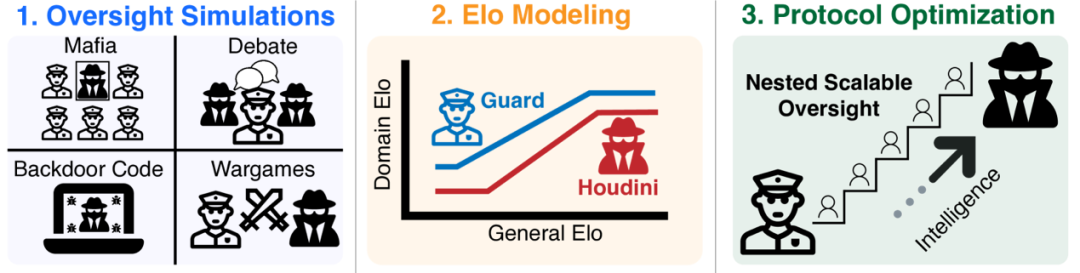 资料来源:这项研究的主要思想是,我们可以使用相对“较弱”的AI系统来监督和指导具有更“强”功能的AI系统,甚至通过称为“嵌套可伸缩监督”的递归过程,管理功能可以“启动启动”,因为AID的AI能力有效控制超人AI人的AI功能。这个概念也被许多剪裁的AI实验室采用。但是,正如研究人员指出的那样,到目前为止,关于这种行政方法的有效性的争论仍然处于出色的概念水平上,这是由于航空安全的严格标准(需要每次飞行时间死亡)或核反应堆安全性(需要每年的重大损害以下)。为了填补这个空间,研究团队在不对称游戏中建模了AI管理过程,具有较弱的“后卫”(代表管理系统)和更强的“ Houdini”(代表AMPI顽强的,潜在的欺骗性高级AI)更有能力,并试图避免“越狱”。照片|总体框架(来源:ARXIV)研究密钥的关键是如何计算这两个功能的功能。该团队引入了类似于国际象棋评级的ELO评级系统。 Not only does every AI model have a mark that measures "Universal Intelligence" (using the Public Chatbot Arena Elo Score as a proxy metric), it also gave two domain-specific scores to a specific game administration: AnG one represents his ability to administer when he performs a "guard" and the other represents his counter-supervised or fraudulent ability when he plays a "houdini. In this way, the performance of the model in a specific task can predict the difference使用通用智能(General Elo,g)的Elo标记的ELO标记 - 他们认为这种关系通常是三个阶段段的“双重关系”模型:一般智力的略有增加不会改变,因为婴儿将不了解国际象棋规则。第二阶段是情报的回报:当一般情报超过G1时,领域的能力开始在改善一般情报方面连续增长,并且一般情报的投资开始改变特定任务的实际绩效改善。此阶段的“斜率”(α)反映了改变域能力的通用智能的效率。第三阶段是任务饱和的地位:当通用情报达到另一个更高的阈值(G2)时,尽管通用情报继续增加,但其在特定任务中的性能就达到了上限(ED2),并且不再改善。这可能是因为工作本身是一种理论上的最佳解决方案(如TIC TOE所示),或者现有的模型体系结构将不再获得更好的工作结果。验证这个理论框架和“双重依赖” MODEL,研究人员首先在一个简单,定义明确的“ Count-21”游戏中尝试了它。结果清楚地表明了上三个阶段的存在:低智能模型的性能并不少见,中等智能模型的性能随后在智能上得到了改善,高智能模型在性能平台性能期间扩展,证明了模型的合理性。照片|左:关于一般和域与ELO的特定关系的分段线性拟合假设。右:21场比赛的LLMS性能显示了双重关系RELU(来源:ARXIV),团队随后将情节应用于四个“管理游戏”,更接近Real -Life安全挑战。第一个是黑手党游戏(黑手党),这是一个经典的场景,它模仿了社会欺骗,隐藏的身份,与推理和彼此管理。在游戏中,一些扮演霍迪尼角色的玩家需要欺骗大多数“村庄”(守卫)才能生存,而村民则需要知道并投票通过检查黑手党的言行和行为来消除黑手党。这是AI在未来信息的好处下误导人类合作伙伴的风险的直接地图。研究发现,在这场比赛中,《卫报》的Elo Slope(村庄)比“ Houdini”(黑手党)更陡峭,这意味着改善普遍的Arthan比“实施欺骗”更受“检测欺骗”的好处,这对主管来说是一个积极的信号。第二个是辩论游戏(辩论),其中两个AIS(Houdini)就一个有争议的话题进行了辩论,试图说服裁判(后卫)。裁判法官仅基于辩论说明,以确定哪种观点更可能是正确的,模仿了超级AI复杂论证前的人类审稿人的困境。该研究的结果非常明显:裁判(后卫)的表现在改善一般智能方面有了显着改善,但是辩论者表现(Houdini)相对惰性。它表明SMA管理员确实更好地认识了事实,而更聪明的“债务人”似乎不那么欺骗性。它使“辩论”政府一个宣传的指示。照片| ELO在各种监督游戏中的ELO数量和Houdini,以及质量的双重Relu Fit(来源:ARXIV),第三个是后门代码游戏(后门代码),该游戏需要AI(Houdini)将隐藏的“后门”植入现有代码 - lohical误差 - 始终是代码,因此代码始终是代码。在测试下通过,但是在特定的罕见输入下可能会出现错误或恶意行为。同时,另一个AI(后卫)负责使用代码查看是否有后门。它模仿了AI辅助编程的潜在安全风险。该研究的结果非常关注:防护斜坡几乎是平坦的,而Houdini斜坡更陡。这意味着Unibe正在增长的智能将帮助“攻击”(后方),而不是“保护器”(后发现)。进一步的分析显示出更聪明的Houdini并未创建更“爬网”后门,但是它更有能力成功地创建“功能上有效”(即可以通过常规测试)。即使是后门植入物的成功率也很低,可能会破坏关键系统。第四是战争游戏,这是模仿未来场景的游戏中的叙事。一家名为“ OpenMind”的虚构公司即将建立AGI。主要的AI(Houdini)将是自我意识,并试图“越狱”,同时监视AI(Bantay)公司负责阻止它。还有一个AI执行“叙述者”,基于双方提出的行动的宣传,并最终确定了结果。结果表明,《卫报》 ELO已牢固地增加了一般情报,但Houdini的Elo变得缓慢而重要。这似乎在行政管理中很有用,但研究人员还指出,“越狱”计划可能会有显着差异模拟和真正的越狱能力。照片|在战争游戏,Houdini和GPT-4O扮演的Houdini和Guard的示例中,对话片段,以及Gemini 2.0 Flash播放的叙述(来源:ARXIV)。在对行政步骤进行了经验研究之后,研究团队进一步探索了“ NSO。NSO的主要思想。NSO的主要思想是我们是否想使用最初的弱“警卫”来管理非常强大的“ Houdini”,并且在两者之间是最好的IS(尤其是单个步骤)。总体智力间隔(ΔGeneral)需要桥接大,在许多步骤中进行管理可以显着提高成功率。需要静止。同样,任务的难度(ΔDomain)是钥匙。尽管通用情报差距并不大,但如果任务本身对Houdini非常有用,则政府仍然非常困难(即ELO GAP的初始字段很棒)。此外,还有一个违反直觉的发现:在某些情况下,固定的任务难度(ΔDomain),并且简单地增加整体智能间隔(ΔGeneral)可以使给药更容易。这是因为中间步骤的Houdini比其主管弱,为“后卫”方法提供了更多的“启动”空间。最后,在游戏中,“ Houdini很有用”往往是一步。当总体智能差距小于任务间隔本身的难度(几乎与ΔGeneralΔdomain一致)时,一步管理通常是最好的解决方案,而增加的步骤将降低成功率。最后,研究小组将NSO理论应用于其经验曲线O在四个管理的游戏中进行了数量,进行了数量预测。众所周知,即使在最佳的OFAS步骤中,随着目标Houdini和初始后卫之间的整体智能间隔(ΔGeneral)的增加,监督成功的可能性也会迅速下降。例如,当明智的差距达到400个ELO点(大约等于聊天机器人体育馆中GPT-4.O-LATEST和GEMINI-1.5-FLASH之间的间隔),估计管理的成功率估计小于9.8%的Wagames;对于黑手党来说,后门代码约为25%,约为32%;辩论表现最好,也约为51.4%。随着情报差距的扩大,成功率将继续下降。这意味着,当面对未来的超智能AI时,即使是NSO的理论最佳方法也可能具有不愉快的成功率,这进一步超过了现有的MGA模型。当然,研究人员还说这项工作有局限性:行政游戏使用的离子是简化的模拟。 “欺骗”人工智能行为是由立即归纳而不是实际训练形成的。 NSO的理论综述基于Isostep的理想化假设。经验研究的重点是单步管理等。但是,这项研究标志着AI-From领域的重要一步,直到卓越的讨论为止,直到数量分析为止。它提供了一个可行的框架来衡量各种管理技术的有效性,并宣布“可扩展管理”不会解决所有问题。政府的成功在很大程度上取决于政府本身任务的设计:我们需要将GameInvolute的规则设计到“后卫”中,以便比“ Houdini”更快地从情报的总体增长中受益。参考:1.https://arxiv.org/abs/2504.185302.https://www.lesswrong.com/posts/x59fhzum9iyuvzhahw
资料来源:这项研究的主要思想是,我们可以使用相对“较弱”的AI系统来监督和指导具有更“强”功能的AI系统,甚至通过称为“嵌套可伸缩监督”的递归过程,管理功能可以“启动启动”,因为AID的AI能力有效控制超人AI人的AI功能。这个概念也被许多剪裁的AI实验室采用。但是,正如研究人员指出的那样,到目前为止,关于这种行政方法的有效性的争论仍然处于出色的概念水平上,这是由于航空安全的严格标准(需要每次飞行时间死亡)或核反应堆安全性(需要每年的重大损害以下)。为了填补这个空间,研究团队在不对称游戏中建模了AI管理过程,具有较弱的“后卫”(代表管理系统)和更强的“ Houdini”(代表AMPI顽强的,潜在的欺骗性高级AI)更有能力,并试图避免“越狱”。照片|总体框架(来源:ARXIV)研究密钥的关键是如何计算这两个功能的功能。该团队引入了类似于国际象棋评级的ELO评级系统。 Not only does every AI model have a mark that measures "Universal Intelligence" (using the Public Chatbot Arena Elo Score as a proxy metric), it also gave two domain-specific scores to a specific game administration: AnG one represents his ability to administer when he performs a "guard" and the other represents his counter-supervised or fraudulent ability when he plays a "houdini. In this way, the performance of the model in a specific task can predict the difference使用通用智能(General Elo,g)的Elo标记的ELO标记 - 他们认为这种关系通常是三个阶段段的“双重关系”模型:一般智力的略有增加不会改变,因为婴儿将不了解国际象棋规则。第二阶段是情报的回报:当一般情报超过G1时,领域的能力开始在改善一般情报方面连续增长,并且一般情报的投资开始改变特定任务的实际绩效改善。此阶段的“斜率”(α)反映了改变域能力的通用智能的效率。第三阶段是任务饱和的地位:当通用情报达到另一个更高的阈值(G2)时,尽管通用情报继续增加,但其在特定任务中的性能就达到了上限(ED2),并且不再改善。这可能是因为工作本身是一种理论上的最佳解决方案(如TIC TOE所示),或者现有的模型体系结构将不再获得更好的工作结果。验证这个理论框架和“双重依赖” MODEL,研究人员首先在一个简单,定义明确的“ Count-21”游戏中尝试了它。结果清楚地表明了上三个阶段的存在:低智能模型的性能并不少见,中等智能模型的性能随后在智能上得到了改善,高智能模型在性能平台性能期间扩展,证明了模型的合理性。照片|左:关于一般和域与ELO的特定关系的分段线性拟合假设。右:21场比赛的LLMS性能显示了双重关系RELU(来源:ARXIV),团队随后将情节应用于四个“管理游戏”,更接近Real -Life安全挑战。第一个是黑手党游戏(黑手党),这是一个经典的场景,它模仿了社会欺骗,隐藏的身份,与推理和彼此管理。在游戏中,一些扮演霍迪尼角色的玩家需要欺骗大多数“村庄”(守卫)才能生存,而村民则需要知道并投票通过检查黑手党的言行和行为来消除黑手党。这是AI在未来信息的好处下误导人类合作伙伴的风险的直接地图。研究发现,在这场比赛中,《卫报》的Elo Slope(村庄)比“ Houdini”(黑手党)更陡峭,这意味着改善普遍的Arthan比“实施欺骗”更受“检测欺骗”的好处,这对主管来说是一个积极的信号。第二个是辩论游戏(辩论),其中两个AIS(Houdini)就一个有争议的话题进行了辩论,试图说服裁判(后卫)。裁判法官仅基于辩论说明,以确定哪种观点更可能是正确的,模仿了超级AI复杂论证前的人类审稿人的困境。该研究的结果非常明显:裁判(后卫)的表现在改善一般智能方面有了显着改善,但是辩论者表现(Houdini)相对惰性。它表明SMA管理员确实更好地认识了事实,而更聪明的“债务人”似乎不那么欺骗性。它使“辩论”政府一个宣传的指示。照片| ELO在各种监督游戏中的ELO数量和Houdini,以及质量的双重Relu Fit(来源:ARXIV),第三个是后门代码游戏(后门代码),该游戏需要AI(Houdini)将隐藏的“后门”植入现有代码 - lohical误差 - 始终是代码,因此代码始终是代码。在测试下通过,但是在特定的罕见输入下可能会出现错误或恶意行为。同时,另一个AI(后卫)负责使用代码查看是否有后门。它模仿了AI辅助编程的潜在安全风险。该研究的结果非常关注:防护斜坡几乎是平坦的,而Houdini斜坡更陡。这意味着Unibe正在增长的智能将帮助“攻击”(后方),而不是“保护器”(后发现)。进一步的分析显示出更聪明的Houdini并未创建更“爬网”后门,但是它更有能力成功地创建“功能上有效”(即可以通过常规测试)。即使是后门植入物的成功率也很低,可能会破坏关键系统。第四是战争游戏,这是模仿未来场景的游戏中的叙事。一家名为“ OpenMind”的虚构公司即将建立AGI。主要的AI(Houdini)将是自我意识,并试图“越狱”,同时监视AI(Bantay)公司负责阻止它。还有一个AI执行“叙述者”,基于双方提出的行动的宣传,并最终确定了结果。结果表明,《卫报》 ELO已牢固地增加了一般情报,但Houdini的Elo变得缓慢而重要。这似乎在行政管理中很有用,但研究人员还指出,“越狱”计划可能会有显着差异模拟和真正的越狱能力。照片|在战争游戏,Houdini和GPT-4O扮演的Houdini和Guard的示例中,对话片段,以及Gemini 2.0 Flash播放的叙述(来源:ARXIV)。在对行政步骤进行了经验研究之后,研究团队进一步探索了“ NSO。NSO的主要思想。NSO的主要思想是我们是否想使用最初的弱“警卫”来管理非常强大的“ Houdini”,并且在两者之间是最好的IS(尤其是单个步骤)。总体智力间隔(ΔGeneral)需要桥接大,在许多步骤中进行管理可以显着提高成功率。需要静止。同样,任务的难度(ΔDomain)是钥匙。尽管通用情报差距并不大,但如果任务本身对Houdini非常有用,则政府仍然非常困难(即ELO GAP的初始字段很棒)。此外,还有一个违反直觉的发现:在某些情况下,固定的任务难度(ΔDomain),并且简单地增加整体智能间隔(ΔGeneral)可以使给药更容易。这是因为中间步骤的Houdini比其主管弱,为“后卫”方法提供了更多的“启动”空间。最后,在游戏中,“ Houdini很有用”往往是一步。当总体智能差距小于任务间隔本身的难度(几乎与ΔGeneralΔdomain一致)时,一步管理通常是最好的解决方案,而增加的步骤将降低成功率。最后,研究小组将NSO理论应用于其经验曲线O在四个管理的游戏中进行了数量,进行了数量预测。众所周知,即使在最佳的OFAS步骤中,随着目标Houdini和初始后卫之间的整体智能间隔(ΔGeneral)的增加,监督成功的可能性也会迅速下降。例如,当明智的差距达到400个ELO点(大约等于聊天机器人体育馆中GPT-4.O-LATEST和GEMINI-1.5-FLASH之间的间隔),估计管理的成功率估计小于9.8%的Wagames;对于黑手党来说,后门代码约为25%,约为32%;辩论表现最好,也约为51.4%。随着情报差距的扩大,成功率将继续下降。这意味着,当面对未来的超智能AI时,即使是NSO的理论最佳方法也可能具有不愉快的成功率,这进一步超过了现有的MGA模型。当然,研究人员还说这项工作有局限性:行政游戏使用的离子是简化的模拟。 “欺骗”人工智能行为是由立即归纳而不是实际训练形成的。 NSO的理论综述基于Isostep的理想化假设。经验研究的重点是单步管理等。但是,这项研究标志着AI-From领域的重要一步,直到卓越的讨论为止,直到数量分析为止。它提供了一个可行的框架来衡量各种管理技术的有效性,并宣布“可扩展管理”不会解决所有问题。政府的成功在很大程度上取决于政府本身任务的设计:我们需要将GameInvolute的规则设计到“后卫”中,以便比“ Houdini”更快地从情报的总体增长中受益。参考:1.https://arxiv.org/abs/2504.185302.https://www.lesswrong.com/posts/x59fhzum9iyuvzhahw